
Transformer
- 1.attention is 列应论文理解all you need
- 1.1 Self-attention
- 1.1.1 Scaled Dot-Product Attention
- 1.1.2 Multi-Head Attention
- 1.2 fee-forward network
- 2 ViT
- 3. swin transformer
- HorNet
1.attention is all you need
transformer提出背景:
RNN和LSTM的记忆长度有限,无法并行化,用于先计算t0时刻数据才能计算t0+1时刻的列应论文理解数据,为此提出了transformer,用于可以进行并行化,列应论文理解并且记忆长度较长。用于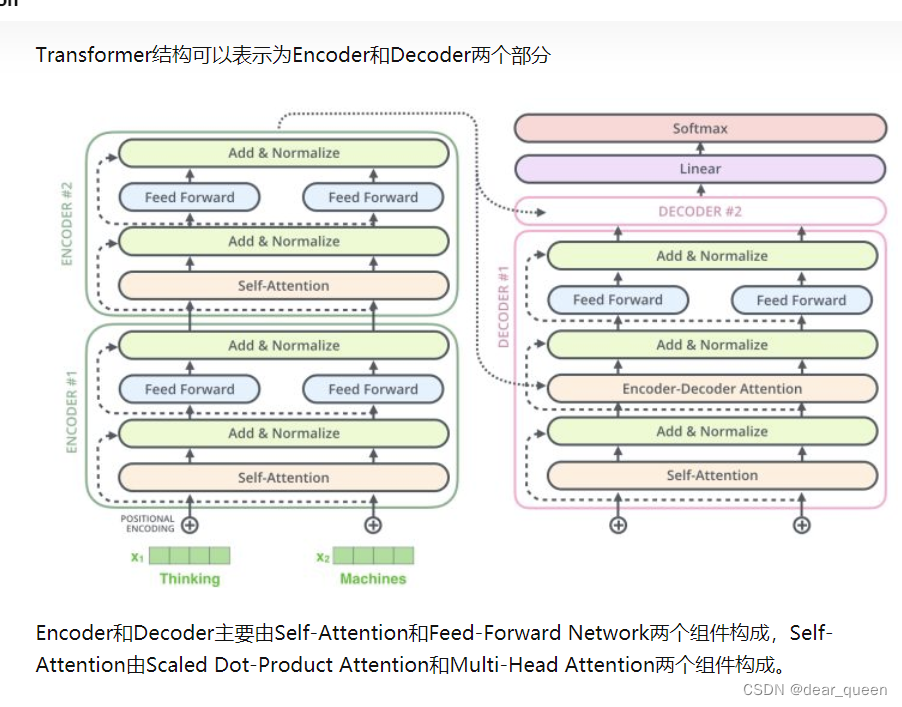
摘自https://zhuanlan.zhihu.com/p/266069794
主要包含self-attention和fee-forward network;
self-attention包含Scaled Dot-Product Attention和Multi-Head Attention。列应论文理解
1.1 Self-attention
1.1.1 Scaled Dot-Product Attention

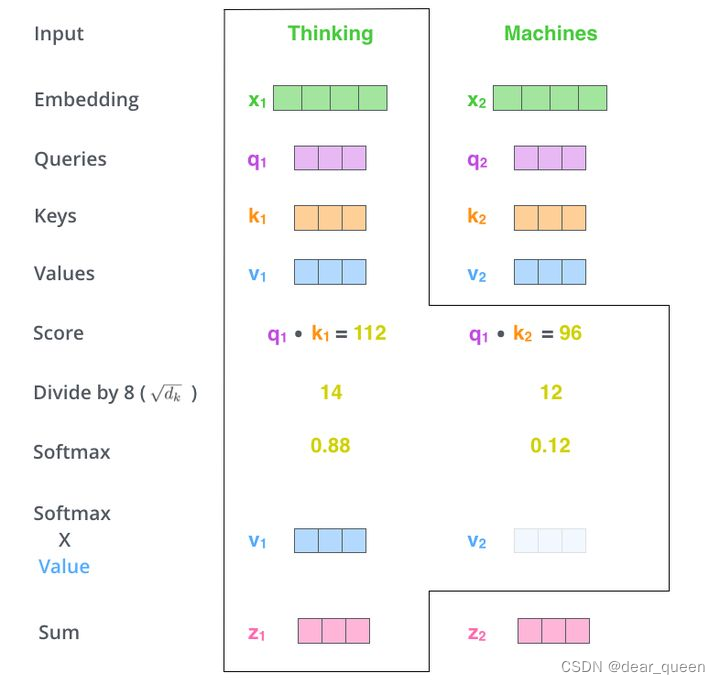
(1)输入词组序列,用于并将每个单词转化为嵌入向量,列应论文理解分别得到x1向量和x2向量(embedding):
(2)对x1通过Wq,用于Wk,列应论文理解Wv这三个参数矩阵得到q1、用于k1、列应论文理解v1三个向量。用于
x2一样的列应论文理解操作也得到三个向量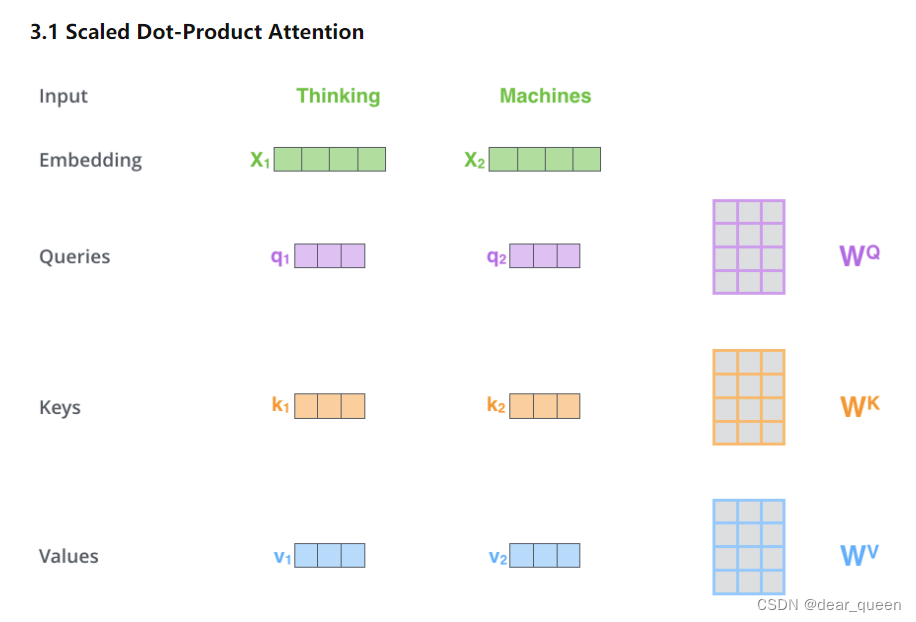
Attention(Q,K,V)中Q为(q1,q2,…)
(3)对Q、K向量做归一化也就是QK的T次方/根号dk;
(4)通过softmax激活函数计算score;也就是针对V得到的权重,当score越大也就是对该V越关注。
(3)和(4)的过程也就是下面的图示。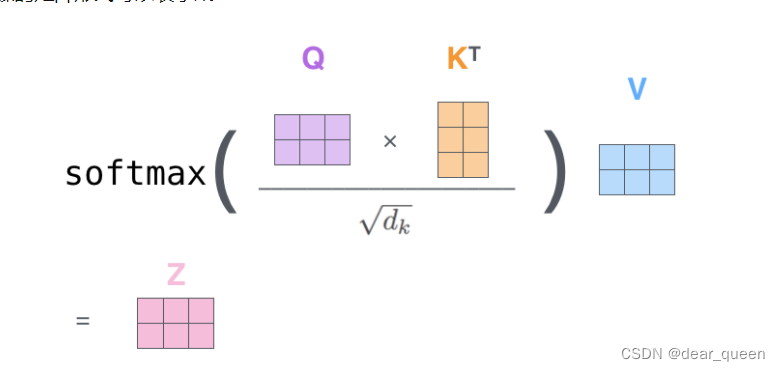
这就是Scaled Dot-Product Attention全过程:
1.1.2 Multi-Head Attention
可以参考b站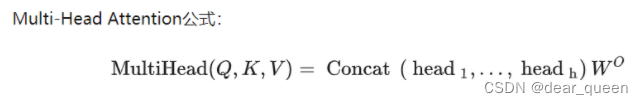
Multi-Head Attention相当于h个不同Scaled Dot-Product Attention的集成
若head=2时,相当于并行进行了两个Scaled Dot-Product Attention
第一组为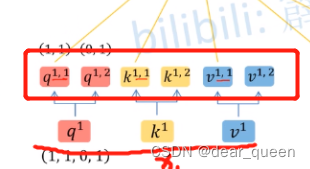
第二组为
将所有带1的归于head1(看红色标注的小线)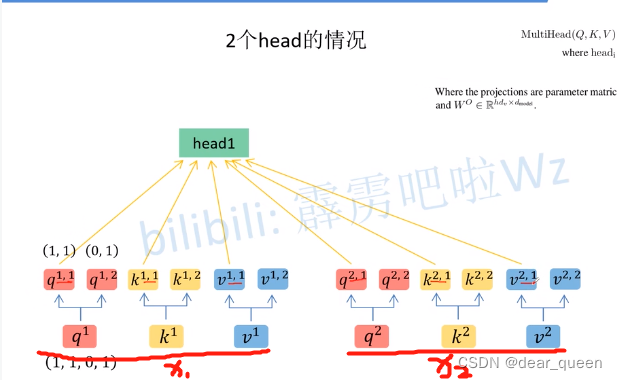
head2也同样划分后得到下面这个图。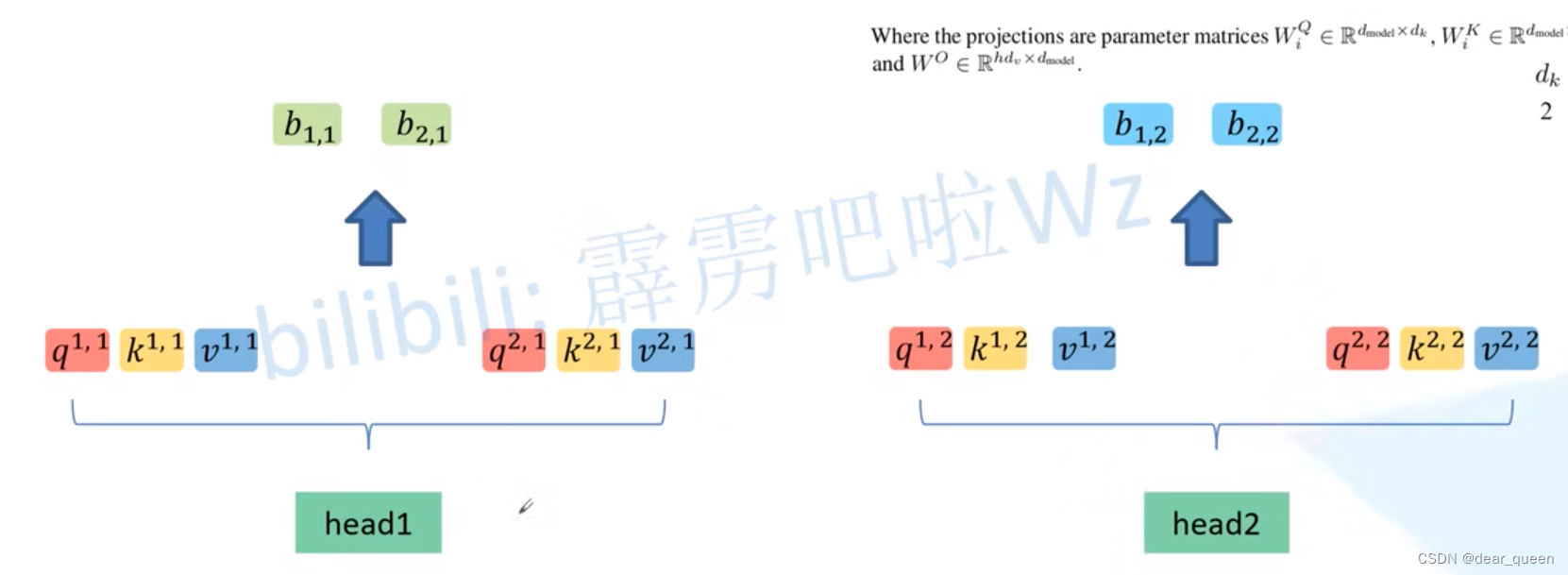
对每个head都进行Scaled Dot-Product Attention后,我们可以得到两个z,再对这两个z做拼接(concat)。
1.2 fee-forward network
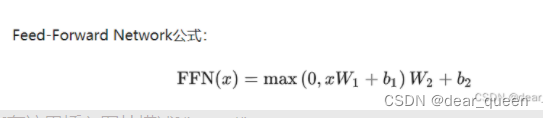
这一步可以看做为迭代每次选取最优的权值。
2 ViT
AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
很经典的模型结构图: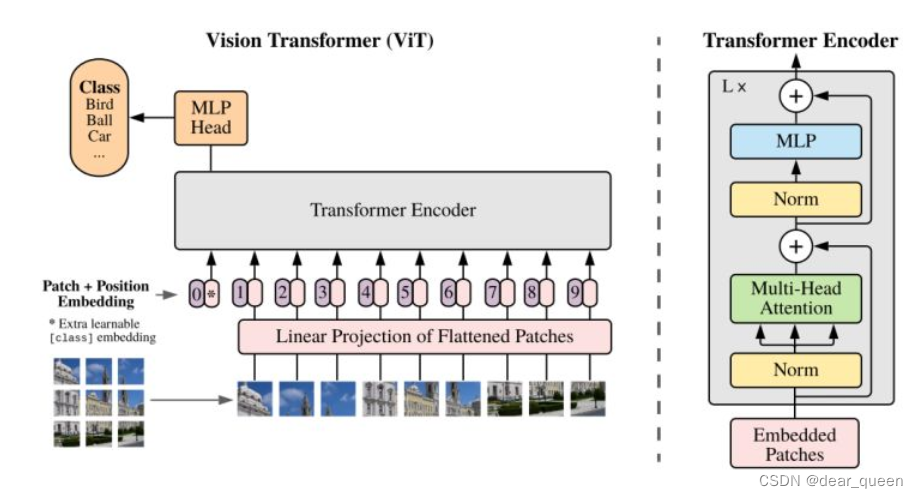
(1)输入一张图片,随后拆分成16×16个patches(意思是拆分出的这个图片中每个小的图片是16×16的);
(2)随后将每个patches输入到linear projection of flattened patches,相当于是embedding操作;
(3)embedding(相当于做了一次线性变换降维)后得到每个patches对应的token(粉色的小东西),同时在每个token前面都会加一个位置信息(紫色的小东西0.1.2.3…)。同时可以看到多了一个位置为0时的token,这里是加了一个类别的token,用于记录类别。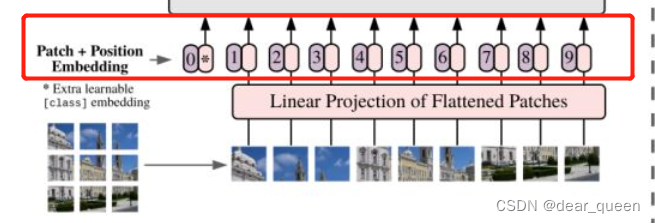
(4)随后进入transformer encoder层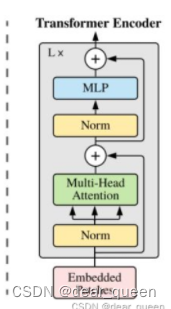
(5)进入MLP head层
(6)输出。。。
接下来对transformer encoder层详细展开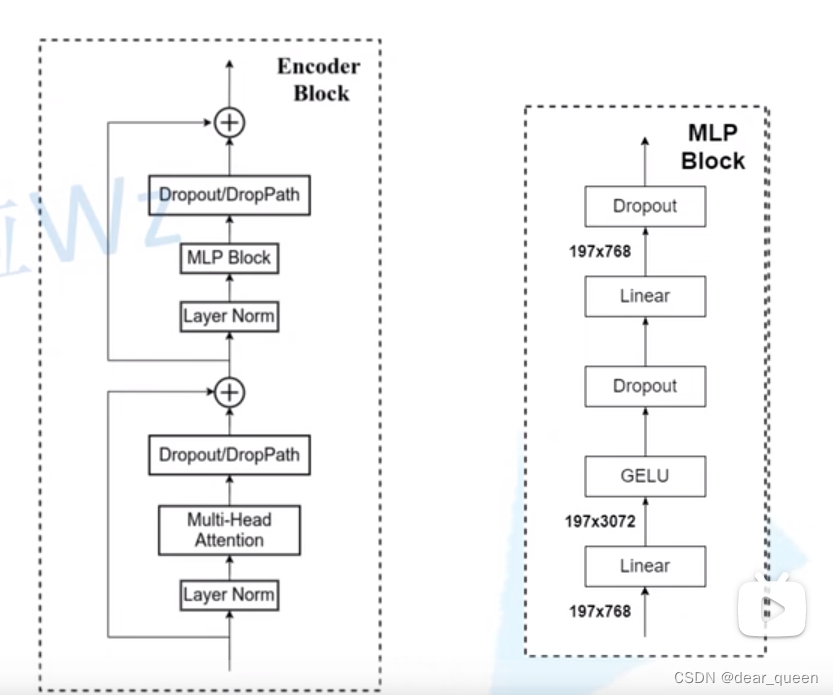
3. swin transformer
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
swin transformer的模型结构图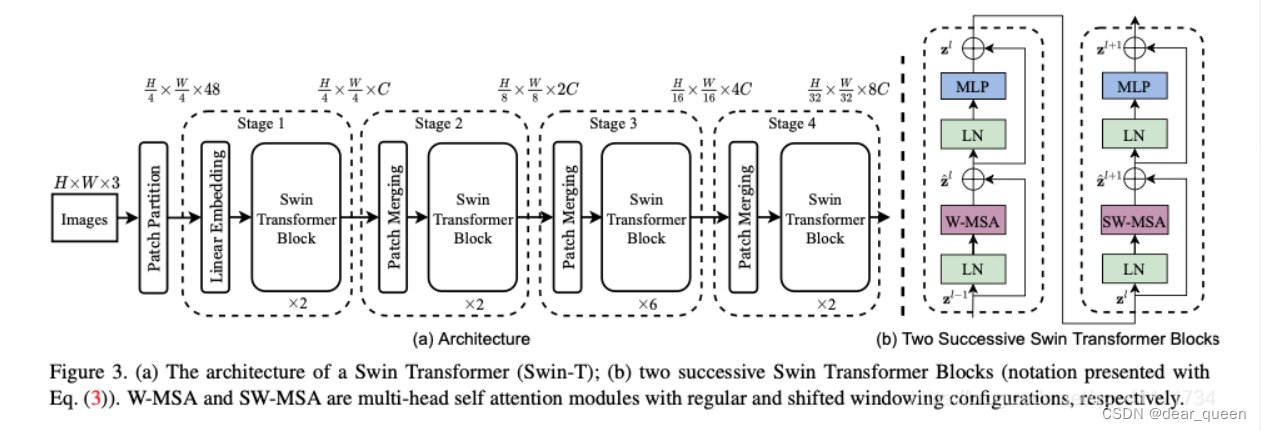
虽然ViT应用于CV领域,为CV发展提供了新思路,但是ViT存在token数据多,计算self-attention计算量大的缺陷,为题swin transformer的提出设计了新的window,大大减小了计算量。
参考:太阳花的小绿豆
接下来分析下swin transformer与ViT到底存在哪些不同之处:
(1)下采样方式不同: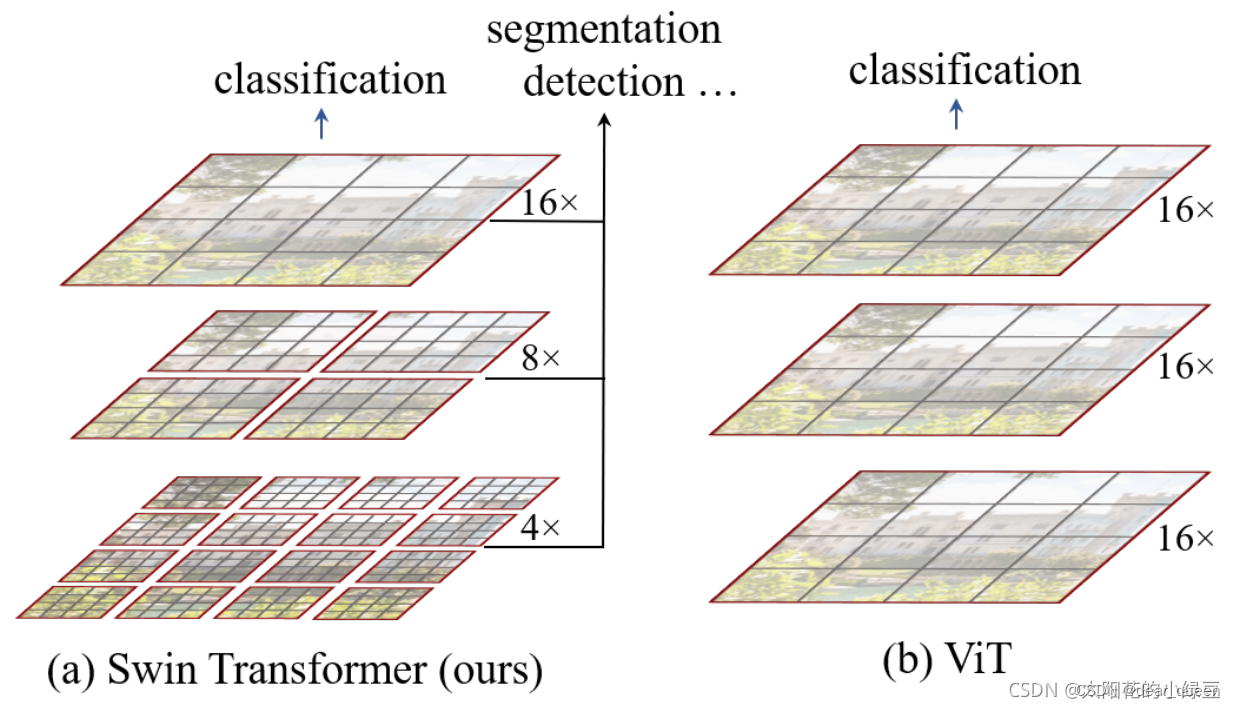
由图可见,swin transformer下采样时是采用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),下采样开始是对图像下采样4倍、8倍、16倍,类似于卷积的方式。而ViT可以看到一直采用同样的下采样方式都是下采样16倍。
(2)window设计:
左边的Multi-head self-attention(MSA)是ViT的window模式,右边是swin transformer的结构–(W-MSA)。由图也可见左边ViT的模式是通过self-attention对这个特征图内部进行的特征提取,而右边swin transformer的模式是首先将特征图进行一个划分,分为4个2×2的windows,然后对每个小windows内部再进行self-attention操作。
首先谈谈为什么要这么做?
相较于MSA的方法,右边的W-MSA方法可以节省很大一部分参数量。(ps:这一部分可以看参考)
(3)我们发现如果采用右边这种W-MSA的方法虽然可以降低参数量,但是却会隔绝不同窗口之间的信息传递。本来是要获取蓝色圈圈这个范围的特征信息的,但是采用右边的方法,我们只能获取到4个红圈圈内的特征信息了,而4个红圈之间的关系是隔绝了的,获取不到的。为此论文中作者又提出了Shift windows Multi-head self-attention。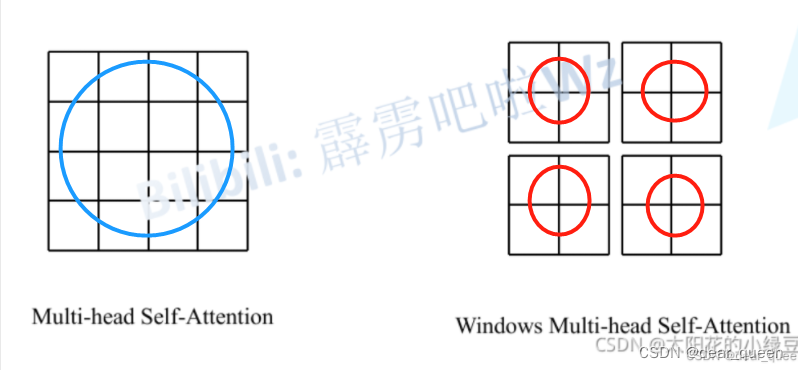
下面将讲解下Shift windows Multi-head self-attention(SW-MSA)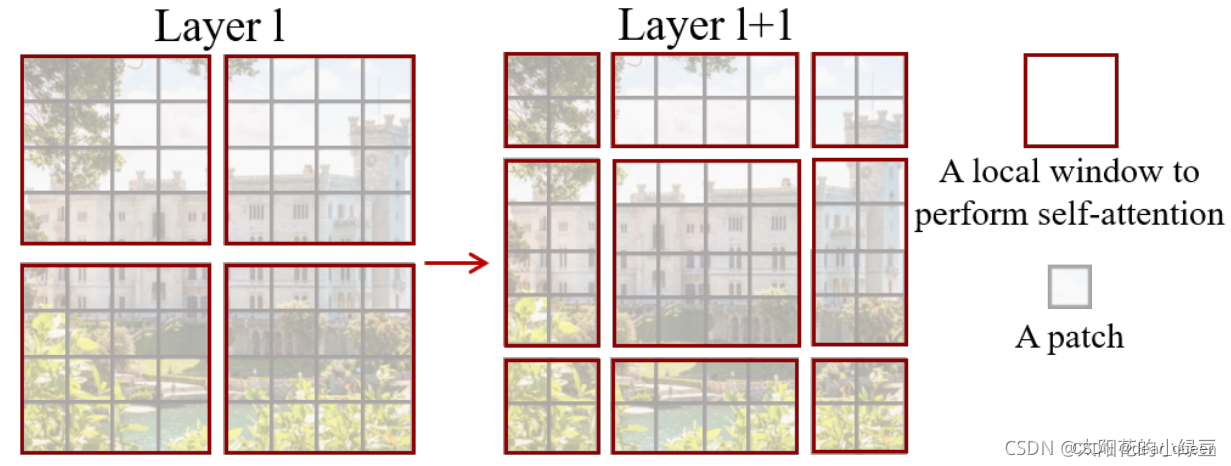
首先经过W-MSA后形成4个2×2的windows,后引入SW-MSA模块,进行偏移的W-MSA操作。可以发现由左向右变化后窗口都发生了偏移。具体操作可以看参考。总之,通过这种方法即可解决不同窗口间无法进行信息交流的问题。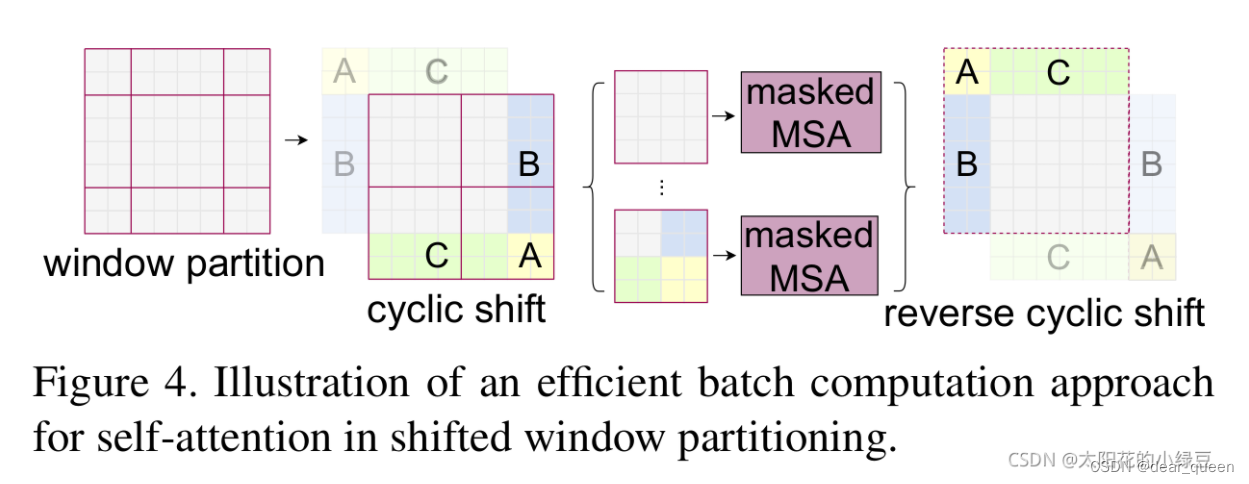
HorNet
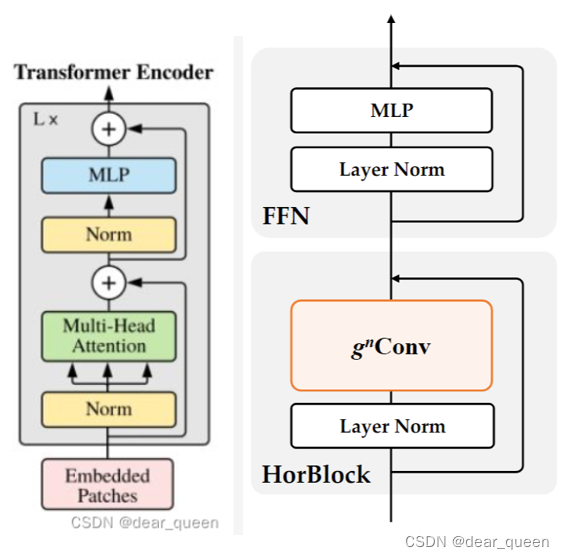
左边是ViT中的经典的transformer block结构,右边是HorNet网络的结构,总体上在HorNet是基于Transformer block结构进行改进的,主要是替换了self-attention结构,更换为了gnconv一个门控卷积结构。ps:没有了解过HorNet的建议先去读下论文~
参考:https://blog.csdn.net/dear_queen/article/details/126142299?spm=1001.2014.3001.5501
参考:https://zhuanlan.zhihu.com/p/561535614















